
Page 119 - 인공지능 수학 교과서
P. 119
인공지능
예측 모델과 분류 모델
이야기
인공지능은 학습을 통해 입력값에 대응하는 출력값을 곧바로 예측할 수도 있고, 또는 입력값이 어느 범주
에 속하는지 예측할 수도 있다.
이 두 가지 예측 상황의 차이에 대해 알아보자.
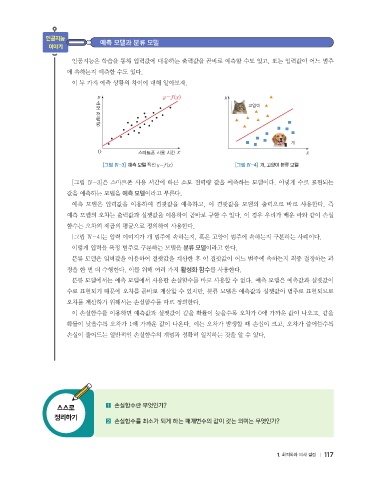
y 소모 y=f(x) y ▲
고양이 ▲
전력량
▲
▲ ▲
▲ ▲ ■
▲
■ ■
■ ■
■ ■
■ ■ 개
O 스마트폰 사용 시간 x x
[그림 Ⅳ-3] 예측 모델 직선 y=f(x) [그림 Ⅳ-4] 개, 고양이 분류 모델
[그림 Ⅳ-3]은 스마트폰 사용 시간에 따른 소모 전력량 값을 예측하는 모델이다. 이렇게 수로 표현되는
값을 예측하는 모델을 예측 모델이라고 부른다.
예측 모델은 입력값을 이용하여 결괏값을 예측하고, 이 결괏값을 모델의 출력으로 바로 사용한다. 즉
예측 모델의 오차는 출력값과 실젯값을 이용하여 곧바로 구할 수 있다. 이 경우 우리가 배운 바와 같이 손실
함수는 오차의 제곱의 평균으로 정의하여 사용한다.
[그림 Ⅳ-4]는 입력 이미지가 개 범주에 속하는지, 혹은 고양이 범주에 속하는지 구분하는 사례이다.
이렇게 입력을 특정 범주로 구분하는 모델을 분류 모델이라고 한다.
분류 모델은 입력값을 이용하여 결괏값을 계산한 후 이 결괏값이 어느 범주에 속하는지 최종 결정하는 과
정을 한 번 더 수행한다. 이를 위해 여러 가지 활성화 함수를 사용한다.
분류 모델에서는 예측 모델에서 사용한 손실함수를 바로 사용할 수 없다. 예측 모델은 예측값과 실젯값이
수로 표현되기 때문에 오차를 곧바로 계산할 수 있지만, 분류 모델은 예측값과 실젯값이 범주로 표현되므로
오차를 계산하기 위해서는 손실함수를 따로 정의한다.
이 손실함수를 이용하면 예측값과 실젯값이 같을 확률이 높을수록 오차가 0에 가까운 값이 나오고, 같을
확률이 낮을수록 오차가 1에 가까운 값이 나온다. 이는 오차가 발생할 때 손실이 크고, 오차가 줄어들수록
손실이 줄어드는 일반적인 손실함수의 개념과 정확히 일치하는 것을 알 수 있다.
손실함수란 무엇인가?
스스로
정리하기
손실함수를 최소가 되게 하는 매개변수의 값이 갖는 의미는 무엇인가?
1. 최적화와 의사 결정 117