
Page 41 - 인공지능 수학 교과서
P. 41
➋ 문장과 단어 사이의 유사성 알아보기
빈도수 벡터를 활용하면 주어진 텍스트 자료에서 중요한 단어나 주제어를 찾을 수
있다. 이 단어들은 해당 텍스트를 대표하는 단어로서 그 문장의 대푯값이 된다.
하나의 문장에 포함된 단어들의 임베딩 벡터의 각 성분별 평균을 구하면 그 문장을
대표하는 벡터를 얻을 수 있다. 이를 활용하여 어떤 단어가 문장이 내포하는 의미와 ▶ 단어 임베딩은 텍스트를
벡터로 표현할 때 의미도
유사한지 아닌지를 판단하는 과정을 살펴보자. 포함할 수 있게 해 주는
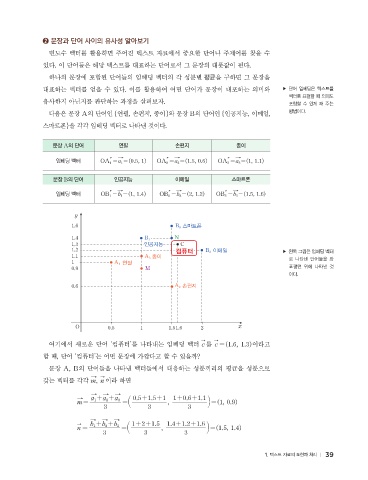
다음은 문장 A의 단어인 { 연필, 손편지, 종이 }와 문장 B의 단어인 { 인공지능, 이메일, 방법이다.
스마트폰 }을 각각 임베딩 벡터로 나타낸 것이다.
문장 A의 단어 연필 손편지 종이
임베딩 벡터 OA_1 =a_1=(0.5, 1) OA_2 =a_2=(1.5, 0.6) OA_3 =a_3=(1, 1.1)
문장 B의 단어 인공지능 이메일 스마트폰
임베딩 벡터 OB_1 =b_1=(1, 1.4) OB_2 =b_2=(2, 1.2) OB_3 =b_3=(1.5, 1.6)
y
1.6 B_3 스마트폰
1.4 B_1 N
1.3 인공지능 C
1.2 컴퓨터 B_2 이메일 ▶ 왼쪽 그림은 임베딩 벡터
1.1 A_3 종이 로 나타낸 단어들을 좌
1 A_1 연필
0.9 M 표평면 위에 나타낸 것
이다.
0.6 A_2 손편지
O 0.5 1 1.51.6 2 x
여기에서 새로운 단어 ‘컴퓨터’를 나타내는 임베딩 벡터 c 를 c =(1.6, 1.3)이라고
할 때, 단어 ‘컴퓨터’는 어떤 문장에 가깝다고 할 수 있을까?
문장 A, B의 단어들을 나타낸 벡터들에서 대응하는 성분끼리의 평균을 성분으로
갖는 벡터를 각각 m, n 이라 하면
a_1+a_2+a_3 0.5+1.5+1 1+0.6+1.1
m= ={ , }=(1, 0.9)
3 3 3
b_1+b_2+b_3 1+2+1.5 1.4+1.2+1.6
n = ={ , }=(1.5, 1.4)
3 3 3
1. 텍스트 자료의 표현과 처리 39